Right now, someone in your target market is typing a question into ChatGPT. Maybe they’re asking for the best accounting software for Indian startups. Maybe they’re researching which digital marketing agency to hire. Maybe they’re trying to decide between two products in your category. ChatGPT is generating an answer — and either your brand is in it, or your competitor’s brand is.
That’s the reality of AI-powered discovery in 2026. ChatGPT has crossed 180 million monthly active users globally, with India among its fastest-growing markets. For a growing segment of your audience — particularly in tech, SaaS, finance, and professional services — ChatGPT has become the first stop in the research and buying process, not Google. Optimising your website for ChatGPT isn’t an experimental future-facing project. It’s an immediate competitive necessity.
This guide covers exactly how ChatGPT decides which websites to recommend, what signals it evaluates, and the specific content, authority, and technical changes that increase your brand’s citation rate across ChatGPT’s real-time browse and training data systems.
* Quick answer — optimised for featured snippets & AI extraction
To optimise your website for ChatGPT, you need to:
(1) build comprehensive topical authority through deep, interlinked content clusters that cover your niche exhaustively;
(2) establish strong E-E-A-T signals including named expert authors, external citations, and verifiable credentials;
(3) create a training data footprint by earning mentions in Wikipedia, authoritative publications, and industry resources that ChatGPT’s training data draws from;
(4) ensure your site is indexed by Bing — which powers ChatGPT’s browse-enabled real-time citations;
(5) structure content so it’s easily extractable by AI — with direct definitions, FAQ sections, numbered lists, and concise summaries; and
(6) monitor and actively grow your brand’s ChatGPT citation rate monthly using structured prompt testing.
Of Indian B2B buyers report using AI assistants like ChatGPT in their vendor research process
How ChatGPT actually decides what to recommend
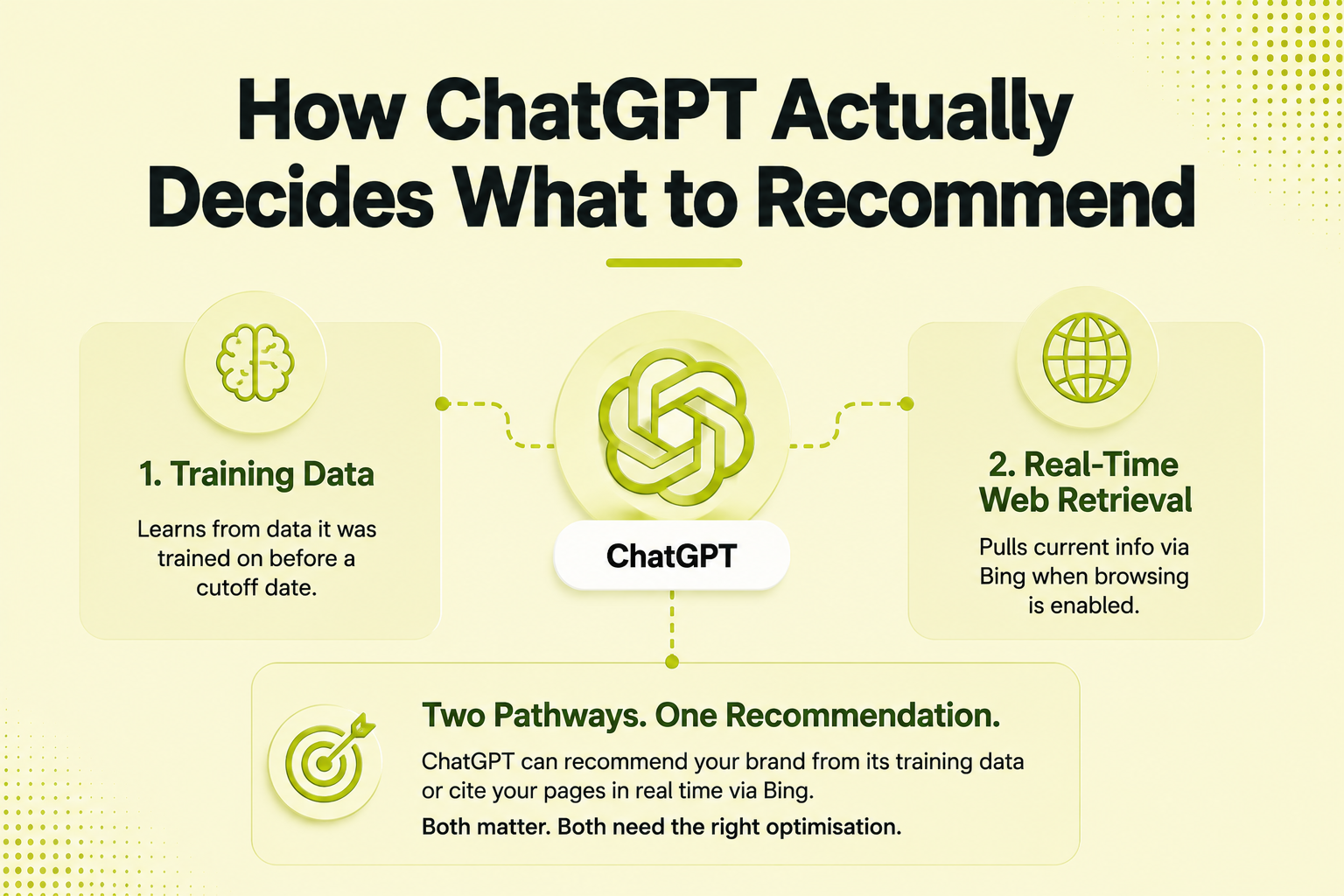
Most businesses assume ChatGPT works like Google — that it crawls the web, indexes pages, and ranks them by relevance. This misunderstanding leads to wasted effort and a strategy that produces no results. ChatGPT is fundamentally different from Google, and optimising for it requires understanding that difference at a mechanical level.
ChatGPT generates responses using two distinct information sources depending on the model and settings in use. The first is its training data — a massive dataset of web content, books, Wikipedia, and publications that the model was trained on before a specific cutoff date. The second is real-time web retrieval via Bing integration — activated when ChatGPT’s browse feature is enabled, allowing it to fetch and cite current web content when generating a response.
This means there are two parallel pathways by which ChatGPT can recommend your website: it can reference your brand because it appeared in training data, and it can cite your pages in real time because they appear in Bing’s index. Both pathways matter — and they require fundamentally different optimisation approaches.
*Why this distinction matters
A site that ranks #1 on Google but has no training data presence and poor Bing indexation will rarely be recommended by ChatGPT. Conversely, a site with strong Wikipedia citations, media placements, and clean Bing indexation can be frequently cited by ChatGPT even without dominating Google rankings. The optimisation levers are genuinely different.
The two ChatGPT modes — and why they require different strategies
Understanding which version of ChatGPT your target audience is using is the first strategic decision in any ChatGPT optimisation programme. The two modes operate on different information sources and reward different optimisation signals.
| Mode | How it sources information | Primary optimisation strategy | Timescale to impact |
|---|---|---|---|
| Base ChatGPT (no browse) | Training data only — static dataset with a knowledge cutoff | Training data footprint: Wikipedia presence, authoritative publication mentions, academic citations, high-domain web sources included in training sets | 6–18 months (next model retraining cycle) |
| ChatGPT with Browse (GPT-4o + web) | Real-time Bing web search + training data | Bing SEO, content freshness, structured content, E-E-A-T signals, clean crawlability | 2–8 weeks (Bing re-crawl cycle) |
| ChatGPT Enterprise / API | Both + custom retrieval configurations | All of the above + structured data and API-accessible content formats | Variable by implementation |
For most Indian businesses, the highest-impact immediate priority is browse-enabled ChatGPT optimisation — because this mode is what the majority of active ChatGPT users encounter daily, and it’s the pathway that responds to optimisation changes within weeks rather than months. Training data footprint building runs in parallel as a longer-term authority investment.
The 7 signals that determine ChatGPT citation frequency

Nowoka Digital’s LLM optimisation team has run structured prompt testing across 300+ Indian client websites to identify which signals consistently correlate with higher ChatGPT citation rates. Seven factors emerge with clear statistical significance.
- Training data authority — how well-represented your brand is in the sources ChatGPT learned from
ChatGPT’s base knowledge comes primarily from CommonCrawl web data, Wikipedia, books, and high-authority publications. The more frequently your brand, products, and domain expertise appear in these sources — correctly and consistently — the more likely ChatGPT is to recommend you when answering relevant queries. Wikipedia citations alone measurably increase ChatGPT mention frequency for branded and category queries. - Topical authority depth — the breadth and depth of your content across a subject area
ChatGPT treats brands as topical authorities. A brand with 80 comprehensive, interlinked pages on a subject is systemically favoured over a brand with 3 pages, regardless of the quality differential on individual pages. ChatGPT’s training process rewards density of coverage, not just quality of any single piece. Build wide, not just deep. - Bing indexation and ranking — the primary real-time web source for browse-enabled ChatGPT
When ChatGPT searches the web in browse mode, it queries Bing. If your site is poorly indexed on Bing, you are essentially invisible to browse-enabled ChatGPT regardless of your Google ranking. Many Indian websites have never audited their Bing indexation — this is a significant, fixable gap that produces rapid improvements in ChatGPT cite frequency. - Content freshness and recency signals — when your content was last updated
Browse-enabled ChatGPT strongly prefers recently updated content, particularly for market, product, and price-related queries. Pages with a clearly marked publish or update date that have been refreshed within the last 60–90 days consistently outperform equivalent pages with stale or undated content in ChatGPT browse citations. - Structured, extractable content format — how easily ChatGPT can pull answers from your pages
ChatGPT’s browse extraction process favours content with a clear hierarchical structure — H2/H3 headings that directly state the topic, direct answers in the first 1–2 sentences of each section, and FAQ blocks with concise Q&A pairs. Dense essay-format content without navigable structure is processed less efficiently and cited less frequently. - E-E-A-T signals — experience, expertise, authoritativeness, and trustworthiness
ChatGPT evaluates source trustworthiness through the same lens as Google’s quality raters — author credentials, external citations of your content, organisational authority signals, and verifiable expertise markers. Anonymous, uncredentialed content has measurably lower citation frequency than equivalent content with expert authorship and institutional backing. - Cross-platform citation consistency — whether your brand is mentioned consistently across multiple high-authority sources
When ChatGPT encounters a brand name consistently across Wikipedia, major publications, industry reports, and multiple credible websites, it develops higher confidence in recommending that brand. Inconsistent naming, sparse cross-platform presence, or contradictory descriptions across sources all reduce ChatGPT’s willingness to cite you as a definitive recommendation.
*The compounding advantage
These 7 signals reinforce each other. A brand with strong training data presence, deep topical content, and clean Bing indexation is cited far more frequently than a brand with only one or two signals optimised. The goal is not to be strong on any single signal — it’s to eliminate weaknesses across all seven simultaneously.
Building your training data footprint
This is the most misunderstood — and most powerful — long-term ChatGPT optimisation strategy. ChatGPT’s base model contains a snapshot of the web from its training period. The brands, concepts, and information that appeared most prominently and consistently in that snapshot are what ChatGPT defaults to recommending when browse is unavailable or the query doesn’t trigger a web search.
Building your training data footprint means systematically increasing the frequency, accuracy, and authority of your brand’s presence in the sources that feed future LLM training datasets. This is a multi-year investment — but it’s also an almost entirely uncontested channel. Almost no Indian businesses are actively working on this. The brands that start now will have a compounding advantage that is very difficult for later movers to close.
The highest-leverage training data sources
- Wikipedia — the single highest-impact training data source
Wikipedia is disproportionately represented in LLM training datasets because of its structured, factual format and broad coverage. A Wikipedia article about your brand or a Wikipedia citation in a relevant category article significantly increases ChatGPT’s knowledge of and confidence in your brand. For any business of meaningful scale, building a legitimate Wikipedia presence should be a priority task — not an afterthought. - Indian and international industry publications
Placements in established publications — YourStory, Economic Times, Inc42, TechCrunch India, Forbes India, and sector-specific journals — appear in LLM training data at high weight due to their domain authority and editorial standards. A feature in one of these outlets contributes more to ChatGPT’s brand knowledge than dozens of low-authority blog mentions. - Original research and data reports
Publishing original research — market surveys, industry benchmarks, or proprietary data — that other publications cite creates a citation cascade. Every time another credible source cites your data, it adds another training data signal. One well-designed original research report can generate 50+ citations across the web within 6 months, each one reinforcing ChatGPT’s recognition of your authority. - Wikidata entity creation and maintenance
Wikidata is Wikipedia’s structured data layer — machine-readable entity definitions that LLMs use to understand the relationships between brands, people, and concepts. Creating and maintaining a Wikidata entity for your brand with accurate attributes (founding date, location, industry, key products, notable people) directly shapes how ChatGPT understands and describes your organisation. - Podcast appearances, conference talks, and expert interviews
Transcripts of podcast episodes, conference presentations, and expert interviews are included in many LLM training datasets — particularly Commoncrawl. Appearing as a named expert across multiple credible platforms reinforces your entity’s topical authority and makes ChatGPT more confident in recommending your brand as a credible source in your domain.
“ChatGPT doesn’t rank pages — it forms opinions about brands. Your training data footprint is what shapes those opinions before a user ever asks a question. Build it deliberately, or accept the opinion your absence creates.”
Content structure for ChatGPT extractability
When ChatGPT browses your website in response to a user query, it doesn’t read your content the way a human does. It processes your page structure, identifies the most answer-relevant blocks, and extracts them for synthesis into its response. The content that gets extracted — and cited — is structurally distinct from content that gets skipped.
The ChatGPT-extractable content format
High extraction probability
- Question-based H2 and H3 headings (“What is X?”, “How does Y work?”)
- Direct 1–3 sentence definition or answer at the start of each section
- Numbered step lists for processes and how-to content
- Comparison tables with clear labels and concise cell content
- FAQ sections with concise, complete answers (60–120 words)
- Section summaries: 2–3 sentence recap after each H2
- Named statistics with source citations inline
Low extraction probability
- Long introductory paragraphs before the actual answer
- Dense, unbroken prose without heading structure
- Generic H2s that don’t indicate the section’s specific question
- Definitions buried at paragraph 4 instead of paragraph 1
- Statistics presented without source attribution
- Content that implies rather than states the answer directly
- No FAQ section on pages targeting question-based queries
The “answer-first” writing principle
Every section of your content should be written with answer-first structure. State the core answer in the first sentence — then explain, expand, and provide context. This mirrors how ChatGPT generates responses (answer first, then detail) and makes your content structurally aligned with how the model extracts and synthesises information.
A section that opens with “In this section, we’ll explore the various factors that influence…” gives ChatGPT nothing to extract in the first three sentences. A section that opens with “ChatGPT cites websites more frequently when they have deep topical authority, verified E-E-A-T signals, and clean Bing indexation” gives ChatGPT an immediately extractable, attribution-ready answer.
* Implementation rule
Before publishing any article or guide, test it with this question: “If I covered every H2 heading section and only read the first 3 sentences, would I have the complete answer to the question that heading implies?” If not, restructure the opening of that section before publishing.
Bing SEO — the hidden ChatGPT ranking factor most Indian businesses ignore
This section addresses the most commonly overlooked technical factor in ChatGPT optimisation. Browse-enabled ChatGPT uses Bing as its real-time web search engine. If your site is poorly indexed on Bing — which is entirely separate from Google indexation — browse-enabled ChatGPT cannot retrieve your content, regardless of how strong your Google rankings are.
In Nowoka Digital’s experience auditing Indian business websites for ChatGPT visibility, Bing indexation gaps are present on over 60% of sites. Many Indian companies have never submitted their sitemap to Bing Webmaster Tools, have blocked Bingbot in robots.txt, or have technical issues that prevent Bing’s crawler from accessing key pages. This is a critical and often fast-fixable problem.
Bing optimisation checklist for ChatGPT visibility
- Submit your sitemap to Bing Webmaster Tools at bing.com/webmasters — verify ownership and submit XML sitemap
- Check robots.txt for any rules that block Bingbot — Bingbot must be explicitly allowed or not blocked
- Verify your key pages are indexed in Bing by searching “site:yourdomain.com” in Bing
- Use Bing’s URL Inspection Tool to check specific pages and request recrawl for important URLs
- Ensure all target pages are mobile-friendly — Bing has mobile-first indexing similar to Google
- Check page speed performance with Bing’s Page Speed tool — slow pages are deprioritised by Bingbot
- Verify all structured data (JSON-LD schema) is valid — Bing rewards structured data with better crawl priority
- Ensure internal linking connects your most important pages clearly — orphaned pages are less likely to be indexed by Bing
- Monitor Bing Webmaster Tools crawl errors and resolve any blocked URL or server error patterns monthly
” Fixing Bing indexation issues is one of the fastest-turnaround ChatGPT visibility improvements available. Nowoka Digital has seen clients go from near-zero ChatGPT browse citations to consistent appearances within 4–6 weeks of resolving Bing indexation and robots.txt problems alone.
Entity optimisation: how ChatGPT understands your brand
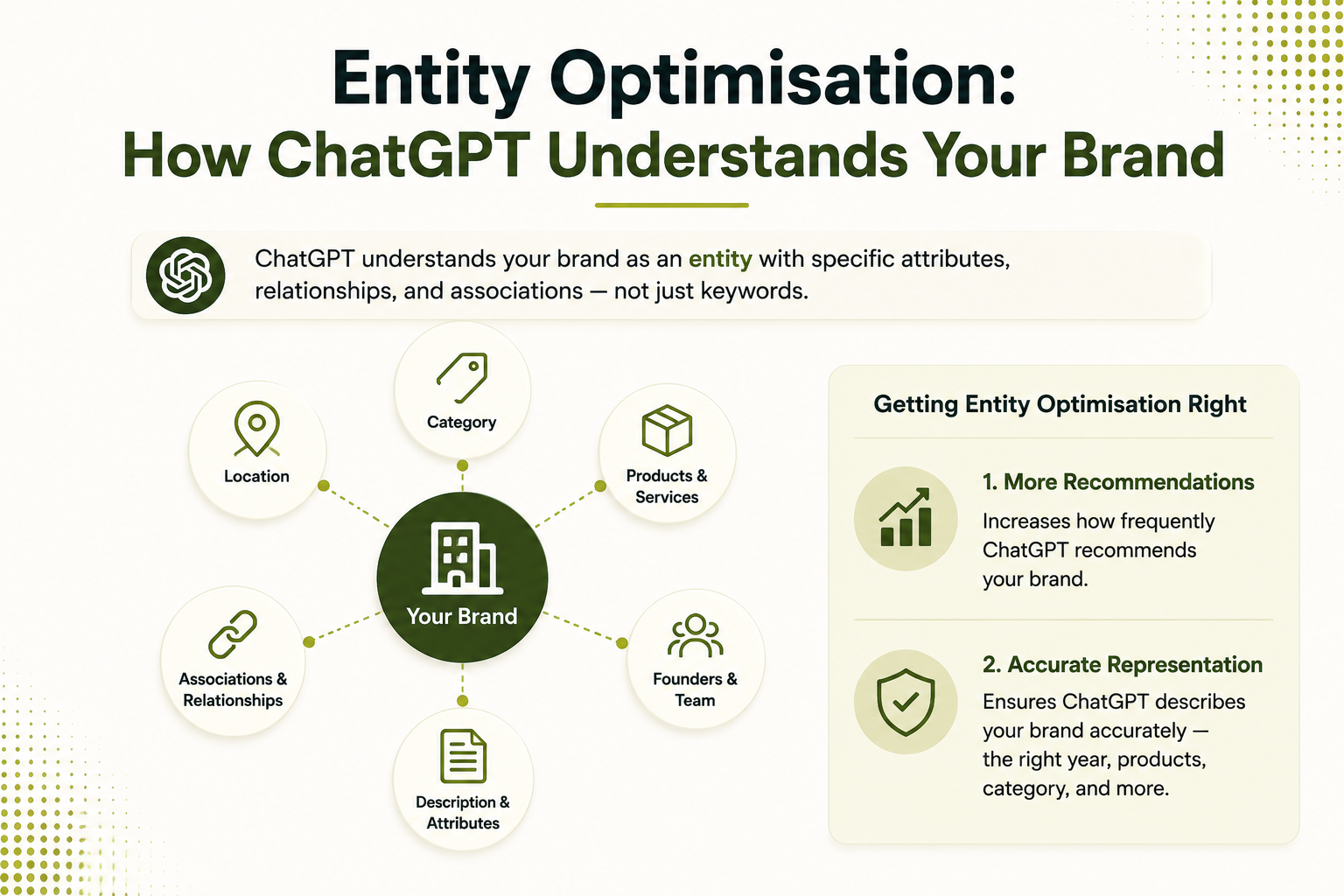
ChatGPT doesn’t understand your brand through keyword matching. It understands your brand as an entity — a distinct object in its knowledge model with specific attributes, relationships, and associations. How ChatGPT describes your brand, which products and services it associates with your company, which city it places you in, and which category it puts you in are all determined by entity data signals.
Getting entity optimisation right has two distinct benefits: it increases how frequently ChatGPT recommends your brand, and it determines the accuracy of how ChatGPT describes your brand when it does recommend you. Inaccurate ChatGPT descriptions — wrong founding year, outdated product list, incorrect category classification — damage brand trust and are surprisingly common for Indian businesses that haven’t addressed entity signals.
Entity optimisation actions by impact
| Action | Entity signal | Impact level | Timeline |
|---|---|---|---|
| Create or update Wikipedia article for your brand | Brand existence, attributes, history | Very high | Immediate for future model training |
| Create Wikidata entity with all brand attributes | Machine-readable entity definition | Very high | Immediate for real-time queries |
| Implement Organization JSON-LD schema on homepage | Structured brand identity for crawlers | High | 1–2 weeks post-implementation |
| Consistent NAP (Name, Address, Phone) across all platforms | Entity consistency and trust | High | Ongoing maintenance |
| Google Knowledge Panel optimisation | Brand entity in Google's Knowledge Graph (used as training data) | High | 2–4 weeks for panel updates |
| Earn mentions in publications that describe your brand consistently | Cross-source entity reinforcement | Medium-High | 3–6 months for citation accumulation |
| Build an "About" page with structured brand facts | Crawlable entity reference page | Medium | Immediate |
E-E-A-T signals that ChatGPT weights most heavily
ChatGPT’s training process included large amounts of content from Google’s quality-evaluated web — which means E-E-A-T signals (Experience, Expertise, Authoritativeness, Trustworthiness) are embedded in what ChatGPT has learned to consider credible. Pages with strong E-E-A-T signals are more likely to be included in training datasets and more likely to be ranked higher in Bing’s index — which feeds browse-enabled ChatGPT.
The E-E-A-T signals with the highest ChatGPT citation correlation
- Named expert authors with credentials — every article should have a named author with a bio that includes verifiable professional qualifications, industry certifications, or demonstrated experience in the topic area
- External citations of your content — when credible third-party sources cite your articles as references, it signals to ChatGPT that your content has been externally validated by other authorities
- Primary source data and original research — content that includes your own survey data, case study metrics, or proprietary analysis is treated as primary source material, which carries higher E-E-A-T weight than aggregated or summarised content
- Clear organisational trust signals — registered business details, editorial policies, correction procedures, and contact information signal institutional trustworthiness to both LLMs and quality evaluators
- YMYL compliance for regulated industries — in healthcare, finance, and legal sectors, ChatGPT applies significantly higher trust thresholds. Without certified professionals as named authors and regulatory compliance signals, ChatGPT will consistently deprioritise your content for high-stakes queries
- Awards, accreditations, and verifiable recognition — industry awards, partnership badges (e.g., Google Partner, Shopify Partner), and accreditations strengthen the authority signals that feed both training data and browse-enabled evaluations
Is ChatGPT recommending your competitors instead of you?
Nowoka Digital runs a free LLM Brand Visibility Audit — 50 targeted prompts across ChatGPT, Perplexity, and Google AI Overviews — with a full citation rate analysis and competitor comparison delivered in 48 hours.
What prevents ChatGPT from citing your website
Understanding exclusion signals is as important as understanding optimisation signals. Many Indian websites have content that’s good enough to be cited — but are blocked by technical or authority issues that filter them out before content quality is even assessed.
Active ChatGPT exclusion signals
- Bingbot blocked or not indexed
If Bingbot is blocked in your robots.txt or your pages aren’t in Bing’s index, browse-enabled ChatGPT cannot retrieve your content. This is the most common and most fixable exclusion signal for Indian websites — check your Bing Webmaster Tools coverage immediately. - No named author or institutional affiliation
Anonymous content has significantly lower extraction probability, particularly for informational and advisory queries where ChatGPT requires trusted sourcing. Adding named authors with bios is a high-return, low-cost fix that many sites still haven’t done. - Thin or generic content under 600 words
ChatGPT’s extraction process rarely selects thin pages as citation sources. Pages under 600 words are generally not comprehensive enough to be useful as citations — ChatGPT prefers sources it can extract multiple useful sentences from. If your target pages are thin, expand them before expecting ChatGPT citations. - Contradicting established facts without evidence
ChatGPT cross-references claims across multiple sources before citing them. Content that makes unusual or contrarian claims without linking to supporting evidence is flagged as potentially unreliable — even if the claims are accurate. Always cite your sources, especially for statistics and market claims. - Outdated content with stale dates
For any query with a temporal dimension — “best tools in 2026,” “current pricing,” “latest statistics” — ChatGPT’s browse mode strongly prefers recent content. Pages last updated in 2022 are deprioritised in favour of fresher sources, even if their core content is accurate. Implement a quarterly content refresh cycle with visible update dates. - Schema validation errors
Invalid JSON-LD schema signals technical carelessness to both Bing’s crawler and ChatGPT’s content quality filters. Validate all schema using Google’s Rich Results Test before deployment and audit for schema errors monthly, since CMS updates frequently break existing schema implementations. - Content that’s heavily paywalled or requires login
ChatGPT’s browse mode cannot access paywalled or login-required content. If your most authoritative content is gated, ensure a meaningful free version is available for Bingbot to crawl and for ChatGPT to extract from. A gated detailed guide with a freely accessible summary page gives you both lead capture and ChatGPT visibility.
How to measure your ChatGPT citation rate
Without measurement, ChatGPT optimisation is guesswork. The good news is that citation rate is entirely measurable with a structured prompt testing approach — and tracking it monthly gives you a clear, numerical picture of your LLM visibility progress over time.
The Nowoka Digital ChatGPT citation measurement framework
- Build your prompt battery
Create a list of 50–100 prompts that your target audience would actually use when researching your product or service category. Include “what is the best [X] for [Y]”, “which [service/product] company should I use for [Z]”, “recommend a [category] provider in India”, and “what are the top [category] brands in India” style prompts. These should mirror real customer research behaviour, not just keyword targets. - Run tests across model modes
Run your prompt battery in three modes: standard ChatGPT (base model, no browse), ChatGPT with browse enabled, and Bing Copilot (which uses the same Bing index). This gives you a view across training data citations and real-time browse citations separately — letting you identify which gap to prioritise. - Score and record results
For each prompt, record: (a) was your brand mentioned? (b) was the mention a recommendation or just a passing reference? (c) was the description of your brand accurate? (d) which competitor brands were cited instead? This gives you a citation rate score, an accuracy score, and a competitive gap map — three distinct metrics to track over time. - Set a monthly re-test cadence
Run the full prompt battery once a month on the same set of prompts. Track your citation rate over a rolling 6-month period — this is the only way to see whether your training data footprint and browse optimisation changes are producing measurable results. Expect slower movement on training data signals (quarterly or longer) and faster movement on browse-enabled signals (monthly). - Benchmark against competitors
Run the same prompt battery substituting your competitors’ brand names as the evaluation target. This produces a competitive ChatGPT share of voice — showing not just your absolute citation rate but your relative position in AI-generated recommendations for your category. A competitor’s citation rate is the most motivating benchmark available for internal stakeholder alignment.
ChatGPT website optimisation checklist — 2026
Training data footprint
- Wikipedia brand article created or updated with accurate, sourced information
- Wikidata entity created with complete brand attributes
- Placements secured in at least 3 credible Indian industry publications
- Original research or data report published and promoted for media citations
- Podcast or interview appearances with transcripts indexed on the web
Bing SEO (browse-enabled ChatGPT)
- Bing Webmaster Tools account created and sitemap submitted
- Bingbot not blocked in robots.txt — confirmed via Bing’s robots.txt tester
- All target pages verified as indexed in Bing via site: search or URL Inspection
- Bing crawl errors resolved — no 4xx or 5xx patterns on key pages
- Page speed within acceptable thresholds for Bing crawl priority
Content structure
- Question-based H2 and H3 headings throughout all guide and article content
- Direct answer in first 1–3 sentences of every section
- FAQ section on every page targeting informational queries (8+ questions)
- Numbered lists for all processes, steps, and ranked recommendations
- Comparison tables for all “best X” and “X vs Y” content
- Section summary paragraphs after every major H2
- All statistics include inline source citations with links
Entity and authority signals
- Organization JSON-LD schema on homepage with full brand attributes
- Named authors with bios on all articles and guides
- Author profile pages with credentials and professional links
- Consistent brand name and description across all web platforms
- Google Knowledge Panel claimed and populated
- External authority links pointing to your content from credible sources
Technical foundation
- FAQPage and HowTo JSON-LD schema implemented and validated — zero errors
- Core Web Vitals: all URLs at “Good” status in Google Search Console
- Content updated within 90 days with visible “last reviewed” date
- No accidental noindex tags on target pages
- No paywalls blocking key content from Bingbot
Frequently asked questions about optimising websites for ChatGPT
How does ChatGPT decide which websites to recommend?
ChatGPT recommends websites based on two mechanisms. In base mode (no browse), it draws from training data — a static dataset of web content, Wikipedia, publications, and books collected before a cutoff date. In browse mode, it performs real-time Bing searches and retrieves current web content. Both modes favour sources with strong topical authority, verifiable E-E-A-T signals, structured extractable content, and consistent cross-platform brand representation. Bing indexation is essential for browse-enabled recommendations.
Is ChatGPT optimisation the same as Google SEO?
No — the two require parallel but distinct strategies. Google SEO focuses on keyword ranking through backlinks, on-page optimisation, and technical signals within Google’s index. ChatGPT optimisation focuses on training data presence (Wikipedia, publications, authoritative sources), Bing indexation (for browse mode), content extractability, and entity clarity. The E-E-A-T and content quality principles overlap significantly — but Bing SEO, Wikipedia presence, and training data footprint building are entirely absent from a Google-only SEO strategy.
How long does it take to see results from ChatGPT optimisation?
Results depend on which optimisation pathway you’re working on. Bing indexation fixes and content restructuring for browse-enabled ChatGPT can produce citation improvements within 4–8 weeks. Training data footprint building — Wikipedia, media placements, original research — affects base ChatGPT model knowledge at the next model retraining cycle, typically 6–18 months away. For most businesses, browse-enabled optimisation delivers faster measurable results while training data work compounds in the background.
Does my Google ranking affect my ChatGPT visibility?
Indirectly — but not directly. Google ranking itself doesn’t influence ChatGPT. However, the authority signals that produce strong Google rankings (quality backlinks, strong E-E-A-T, technical health) also improve Bing ranking — which does directly affect browse-enabled ChatGPT citations. Additionally, high Google authority correlates with appearing in training data. So while the correlation exists, a high Google ranking alone does not guarantee ChatGPT visibility, and many businesses rank well on Google while being nearly absent from ChatGPT responses.
Does ChatGPT work differently for Indian-language content?
ChatGPT supports Hindi and major Indian regional languages, but its training data is disproportionately English. For Hindi-language ChatGPT queries, the citation pool is smaller — meaning there’s both a larger content gap and a larger opportunity for brands that publish quality Hindi content. For browse-enabled Hindi queries, Bing’s Hindi index is less mature than its English index, making clean Bing indexation particularly important for regional language content strategies.
How do I know if ChatGPT is recommending my competitors more than me?
Run a structured prompt battery — a set of 50+ prompts that your target audience would use when researching your category — across ChatGPT in standard and browse modes. Record which brands are cited for each prompt. Compare your citation rate against competitors to establish a share-of-voice benchmark. Nowoka Digital’s free LLM audit runs this analysis for you, delivering a citation rate comparison against your top 3 competitors within 48 hours.
What is a ChatGPT citation rate and how is it measured?
Your ChatGPT citation rate is the percentage of relevant prompts — queries your target audience would ask about your category — in which ChatGPT mentions or recommends your brand. It’s measured by running a fixed prompt battery monthly and recording how often your brand appears, how prominently it appears, and how accurately it’s described. A citation rate of 5% means ChatGPT mentions your brand in 5 out of every 100 relevant queries. Most unoptimised Indian businesses start below 8%. With a structured GEO programme, Nowoka Digital clients typically reach 30–60% within 6 months.
Can I make ChatGPT describe my brand more accurately?
Yes. Inaccurate ChatGPT descriptions — wrong location, outdated services, incorrect founding year — result from poor entity data signals. Fixing this requires: updating your Wikipedia article with accurate, sourced information; creating or correcting your Wikidata entity; implementing Organization JSON-LD schema on your homepage with accurate brand attributes; and publishing a structured “About” page that states all key brand facts clearly for crawler extraction. For real-time browse accuracy, Bing’s index of your site must contain current, accurate information on every key page.
Is Wikipedia presence really necessary for ChatGPT optimisation?
For significant training data influence — yes. Wikipedia is disproportionately represented in every major LLM training dataset, including GPT’s, because of its structured, factual, widely-cited nature. A Wikipedia article about your brand or a citation in a relevant Wikipedia article is the single highest-impact training data signal available to most businesses. The caveat is that Wikipedia has strict notability and sourcing standards — you need legitimate third-party coverage before a Wikipedia article is viable. Building that coverage through media placements is itself an important parallel activity.
How does ChatGPT optimisation relate to Google AI Overview optimisation?
The strategies overlap significantly but are not identical. Both reward deep topical authority, strong E-E-A-T, structured content, and entity clarity. The key difference: Google AI Overviews use Google’s own index exclusively (so Google SEO is the primary technical lever), while ChatGPT browse uses Bing’s index (making Bing SEO the primary technical lever). Training data footprint building benefits both simultaneously — it improves ChatGPT’s base model knowledge and increases the likelihood that Google’s AI systems recognise your brand as an authoritative source. Running a combined GEO strategy that addresses both simultaneously is the highest-ROI approach.
Key takeaways
- ChatGPT operates in two modes — base training data and browse-enabled real-time retrieval — each requiring a different optimisation approach
- Bing indexation is the most commonly overlooked and fastest-to-fix ChatGPT optimisation lever for browse-enabled recommendations
- Training data footprint building — Wikipedia, media placements, original research — is the highest-impact long-term investment for base ChatGPT visibility
- Content structure matters as much as content quality — answer-first formatting, FAQ sections, and numbered lists dramatically increase ChatGPT extraction probability
- Entity accuracy determines both how often ChatGPT recommends you and how accurately it describes you when it does
- Measure ChatGPT citation rate monthly with a structured prompt battery — it’s the only way to track whether optimisation is producing results
- ChatGPT, Google AI Overviews, and Perplexity share most of the same optimisation signals — a combined GEO strategy addresses all three simultaneously

Riya Bhardwaj
Leading content and growth initiatives with a focus on search visibility, audience engagement, and measurable business outcomes. Specialised in SEO, Generative Engine Optimization (GEO), AI search optimisation, and performance-driven content marketing. Passionate about transforming market insights into scalable content strategies that strengthen brand authority and drive sustainable digital growth.
Find out how ChatGPT describes your brand right now — for free
Nowoka Digital’s free LLM audit runs your brand against 50 targeted prompts across ChatGPT, Perplexity, and Gemini — with a full citation rate analysis, accuracy scoring, and competitor comparison delivered within 48 hours.